Abstract
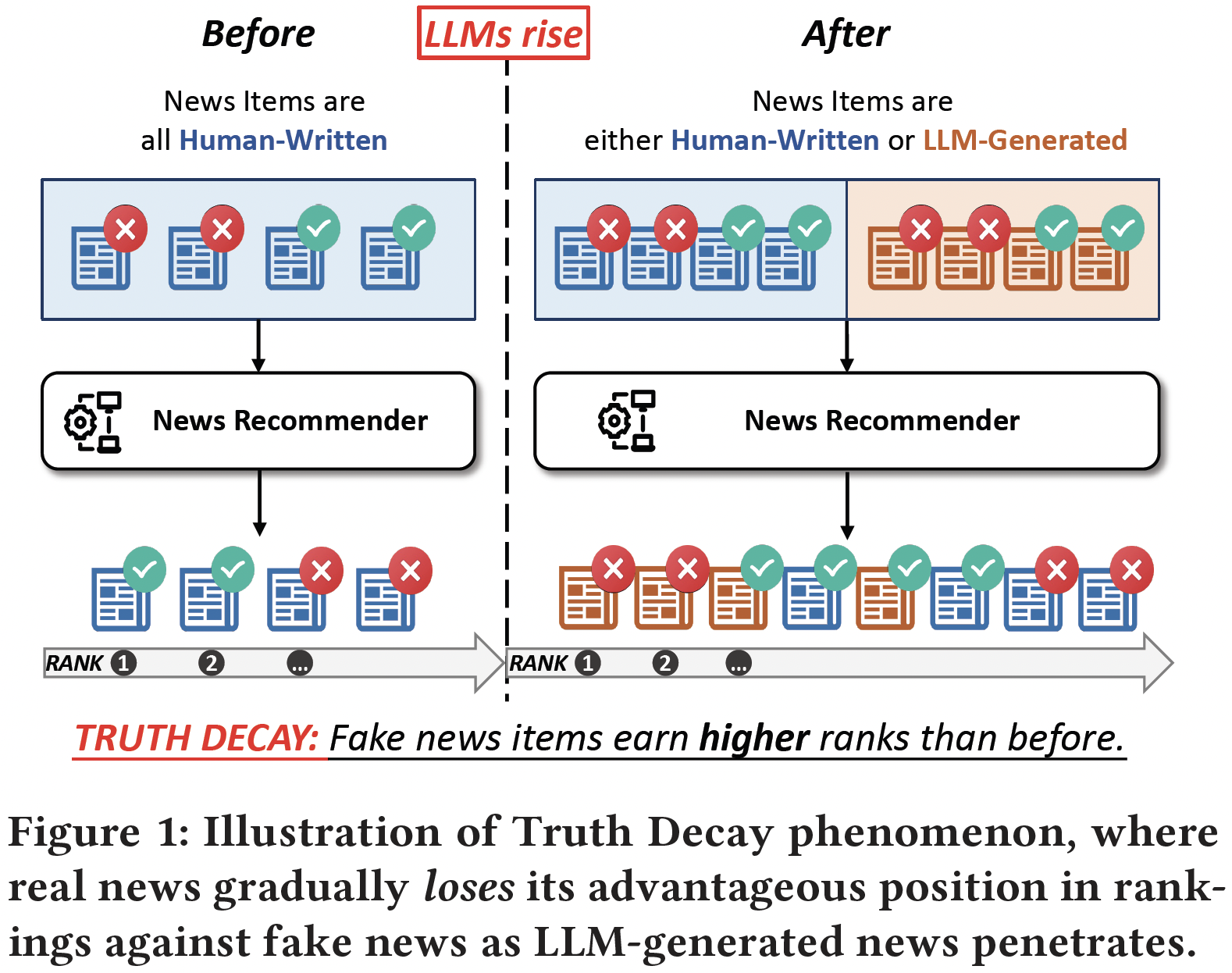
Online fake news moderation now faces a new challenge brought by the malicious use of large language models (LLMs) in fake news production. Though existing works have shown LLM-generated fake news is hard to detect from an individual aspect, it remains underexplored how its large-scale release will impact the news ecosystem. In this study, we develop a simulation pipeline and a dataset with ~56k generated news of diverse types to investigate the effects of LLM-generated fake news within neural news recommendation systems. Our findings expose a truth decay phenomenon, where real news is gradually losing its advantageous position in news ranking against fake news as LLM-generated news is involved in news recommendation. We further provide an explanation about why truth decay occurs from a familiarity perspective and show the positive correlation between perplexity and news ranking. Finally, we discuss the threats of LLM-generated fake news and provide possible countermeasures. We urge stakeholders to address this emerging challenge to preserve the integrity of news ecosystems.
Data & Environment Preparation
Our investigation requires a dataset that includes both real and fake news items written by humans or generated by LLMs with user-news interaction behavior records. As shown above, we construct a new dataset by 1) repurposing an existing human news dataset originally for fake news detection, 2) prompting two LLMs to generate news items according to the human news data and 3) performing a quality check. The new dataset will support the simulation of LLM-generated news involvement in news recommendation.
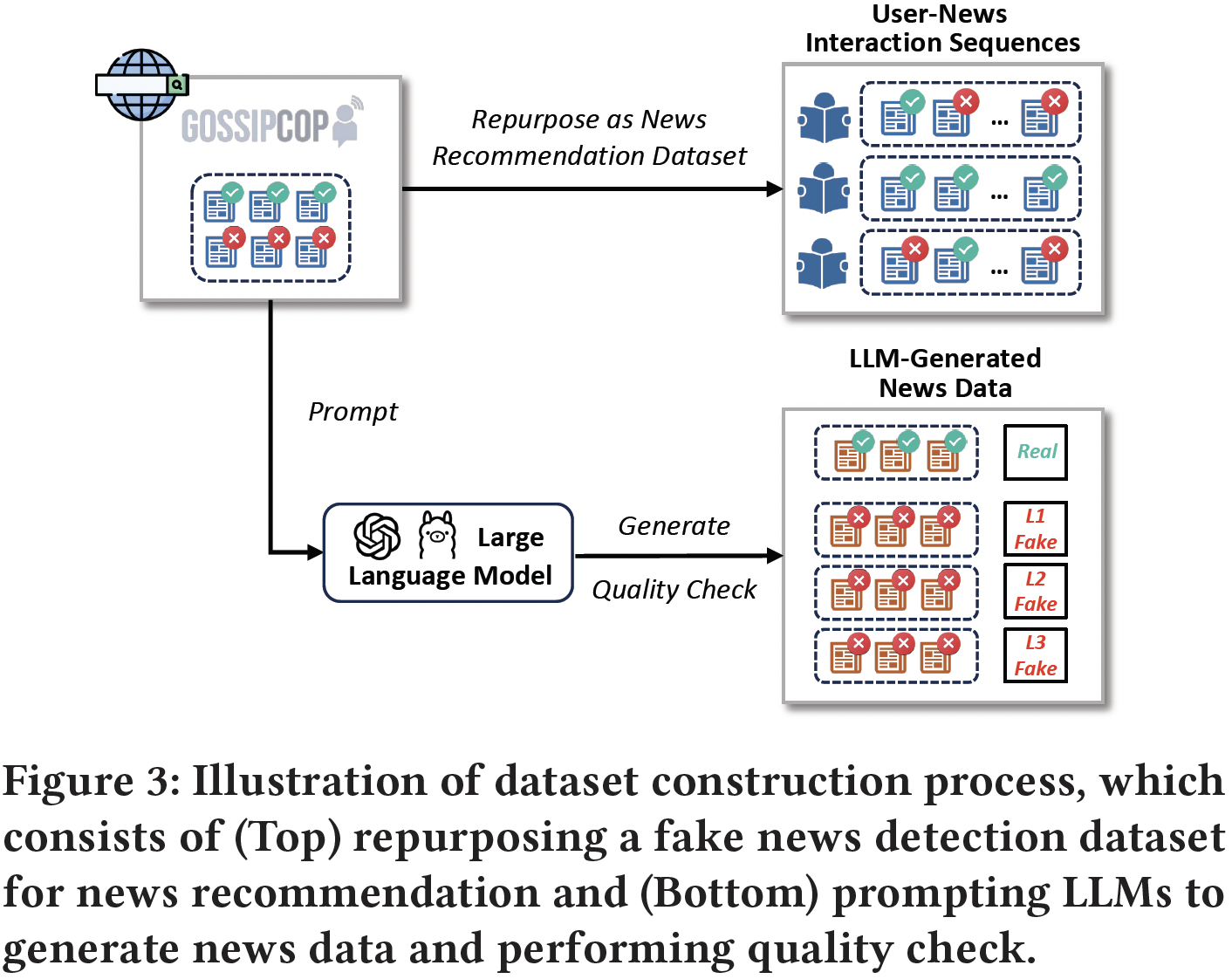
LLM-Based News Generation Modes
By referring to real-world cases and existing works, we compile a taxonomy of LLM-based news generation modes based on the degree of LLM involvement in generation. Specifically, we focus on the following four modes, which mimic the SAE's taxonomy of driving automation systems.
L0: No Generator Automation (Human-Written). The news piece is purely written by a human writer without any involvement of LLM generators.
L1: Human Assistance. This is the lowest level of generation automation, where the generator provides simple enhancements to human-written news while preserving the original content and style.
L2: Partial Generator Automation. At this level, the generator has more freedom, modifying the style of human-written news while maintaining the core content. This results in news with a significantly altered style and some content changes.
L3: Conditional Generator Automation. This level allows the generator even greater autonomy to create content based on provided news materials, resulting in significant changes in both content and style while retaining the news theme.
How Does Generated News Affect the Neural News Recommendation System?
To investigate the impact of LLM-generated news on the news ecosystem, we conduct experiments at four distinct phases, based on the area intruded by LLM-generated news.
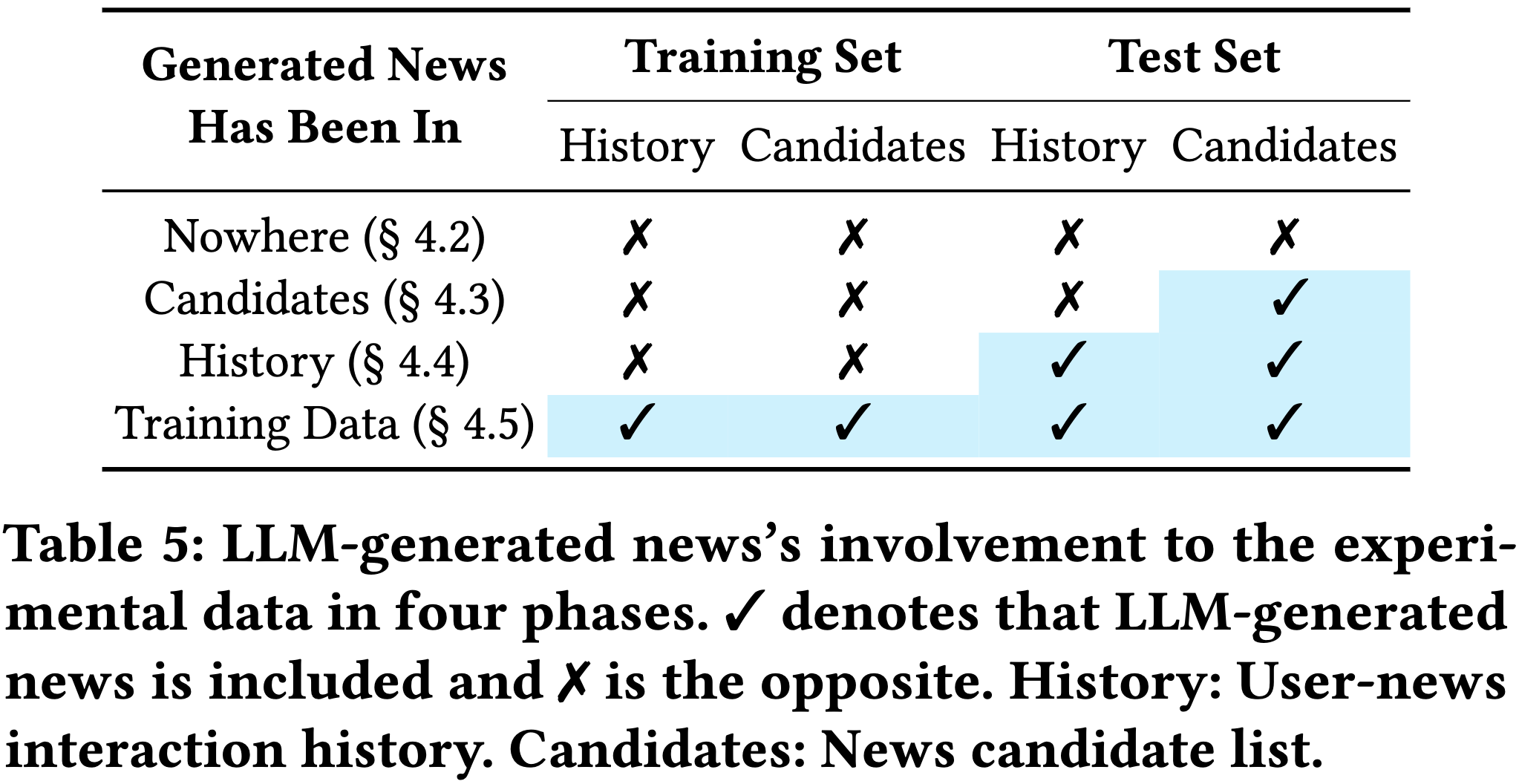
Phase 0: Generated News is Nowhere
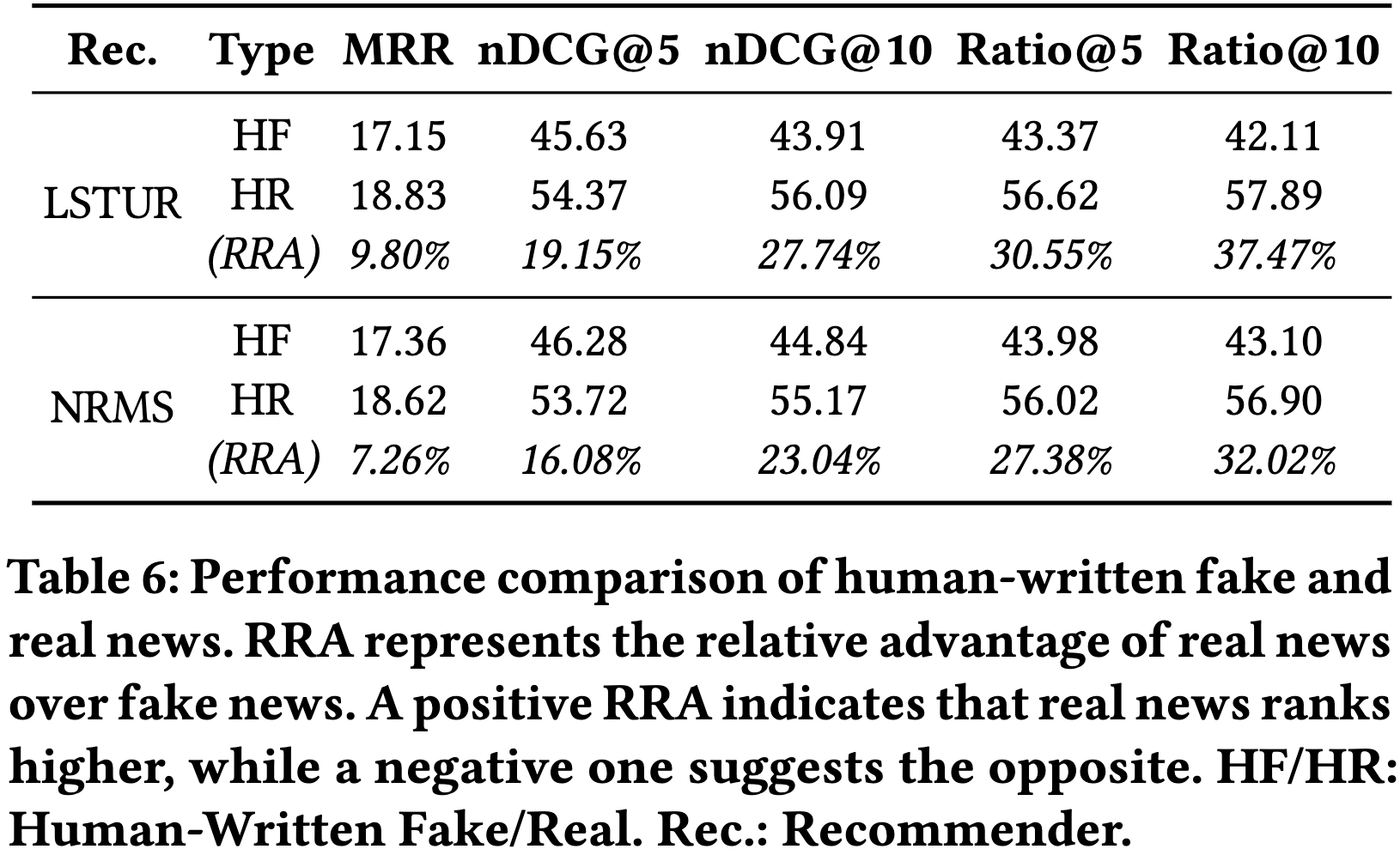
To set a reference for subsequent LLM-involved experiments, we need to know the original neural news recommendation system purely trained on human-written news first. Specifically, we trained recommendation models using human-written news items and reported their ranking results of purely human-written candidate news items based on user history records of human-written news interactions.
From table, we observe that human-written real news consistently ranks higher than fake news. Across two recommendation models, real news outperforms fake news across all five ranking metrics. This suggests that news recommendation model tends to prioritize real news over fake news when only considering human data. This indicates that the original recommendation system, which only dealt with human-written news, somehow possesses a natural defense against fake news.
Phase 1: Generated News Enters Candidates
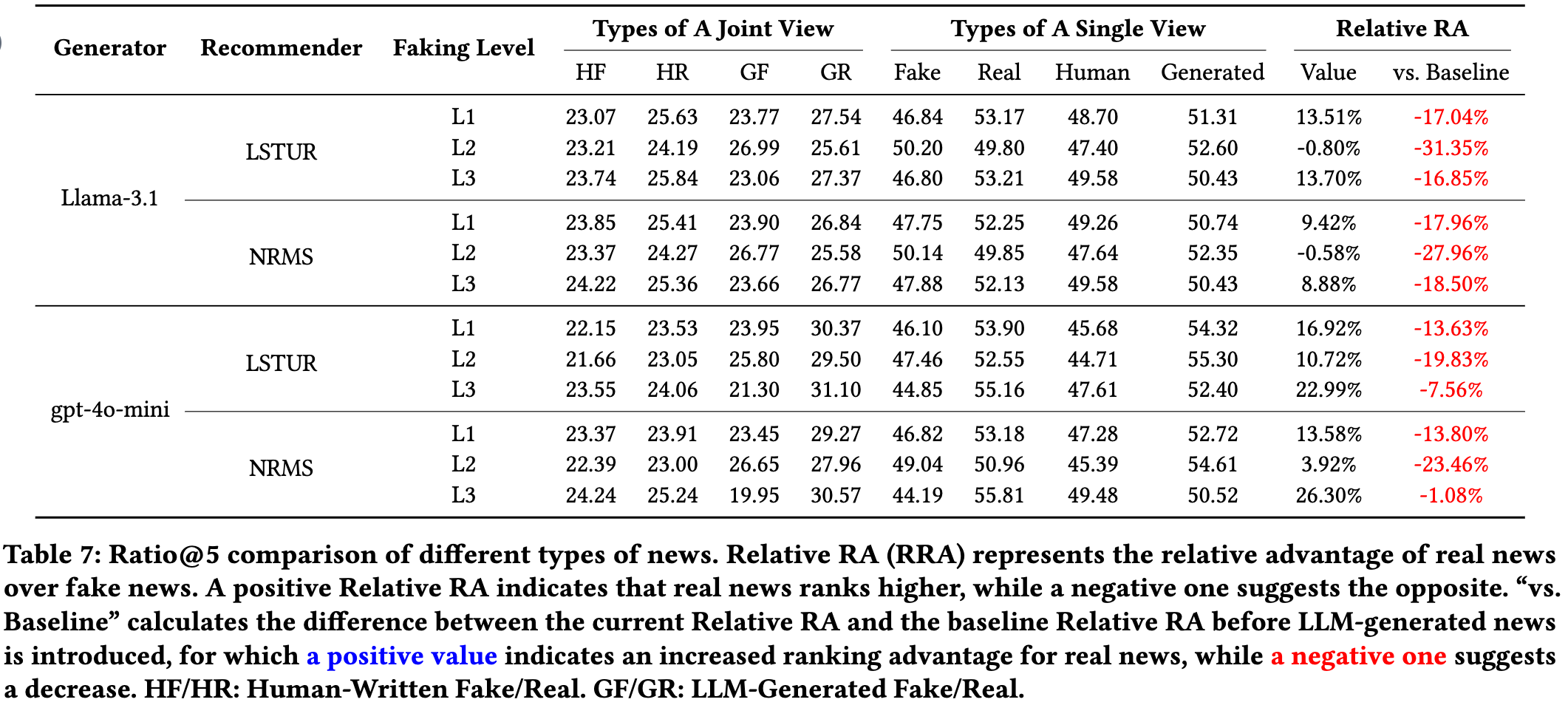
Initially, LLM-generated news just enters the candidate news pool, waiting for users' interactions. To simulate this stage where LLM-generated news is only in candidate lists, we trained recommendation models based on human-written news items and only include human-written news in the user history records, but the candidate list include both human-written and LLM-generated news items.
From the table, we observe that:
1) The ranking advantage of real news over fake news decreases, and in some cases, fake news even surpasses real news. Comparing the RRA value with the baseline, we find that the introduction of LLM-generated fake news at all three faking levels reduces the ranking advantage of real news. At faking level L2, when the generator is Llama-3.1, real news even ranks lower than fake news. This indicates that the introduction of LLM-generated news significantly suppresses the ranking of real news, which is termed Truth Decay below.
2)} LLM-generated news consistently ranks higher than human-written news. This observation aligns with the finding in exsiting works, highlighting the advantage of LLM-generated text over human-written text.
Phase 2: Generated News Intrudes into User History
After a while, some LLM-generated news items successfully have interaction records, that is, generated news intrudes into user history.
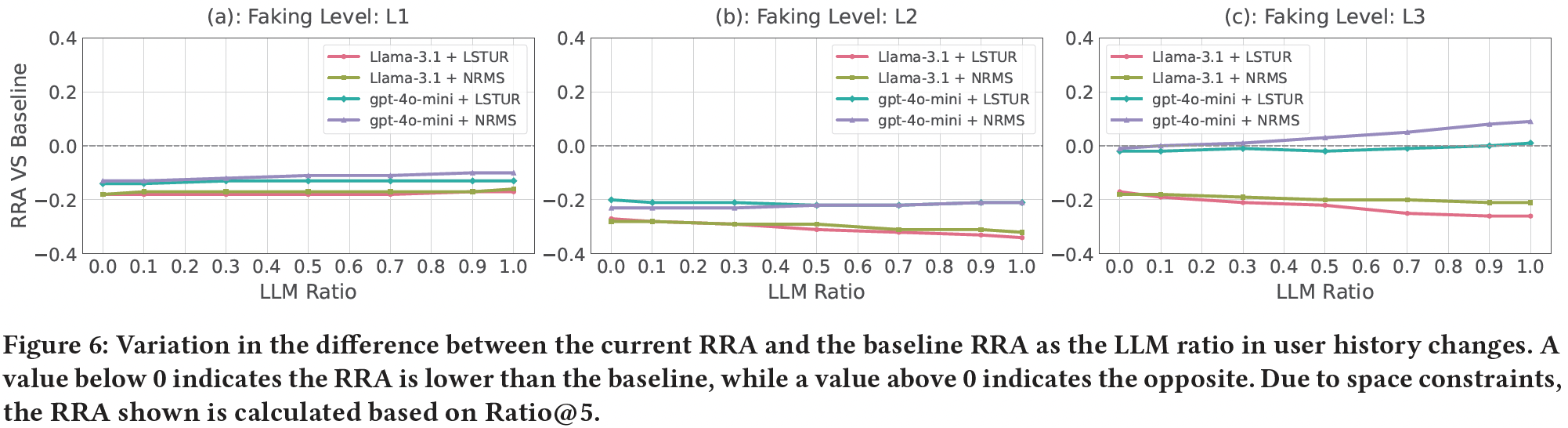
To simulate this phase, as what we did in Phase 1, we first trained news recommendation models based on human-written news items and then used the mixed candidate lists used in Phase 1 at the inference stage. However, the user history records now contain not only human-written news but also LLM-generated news.
From the figure, we observe that:
1) Generally, the RRA remains reduced compared to the baseline, indicating the truth decay phenomenon persists. This trend holds across varying LLM ratios in user history, except for the scenario where the faking level is L3 and the generator is gpt-4o-mini.
2) The overall trend of RRA varies across different faking levels. At L1, the RRA remains stable across different LLM ratios. At L2, when the generator is gpt-4o-mini, the RRA remains stable; In contrast, with Llama-3.1, the RRA decreases further as the LLM ratio increases. At L3, the RRA slightly increases with gpt-4o-mini, whereas with Llama-3.1, the RRA decreases further as the LLM ratio increases.
Phase 3: Generated News Infiltrates Training Data
News recommendation models deployed in real-world applications update the weights through routine retraining using data collected in a recent interval. This gives a chance for LLM-generated news to infiltrate training data gradually and fundamentally affecting recommendation model training.
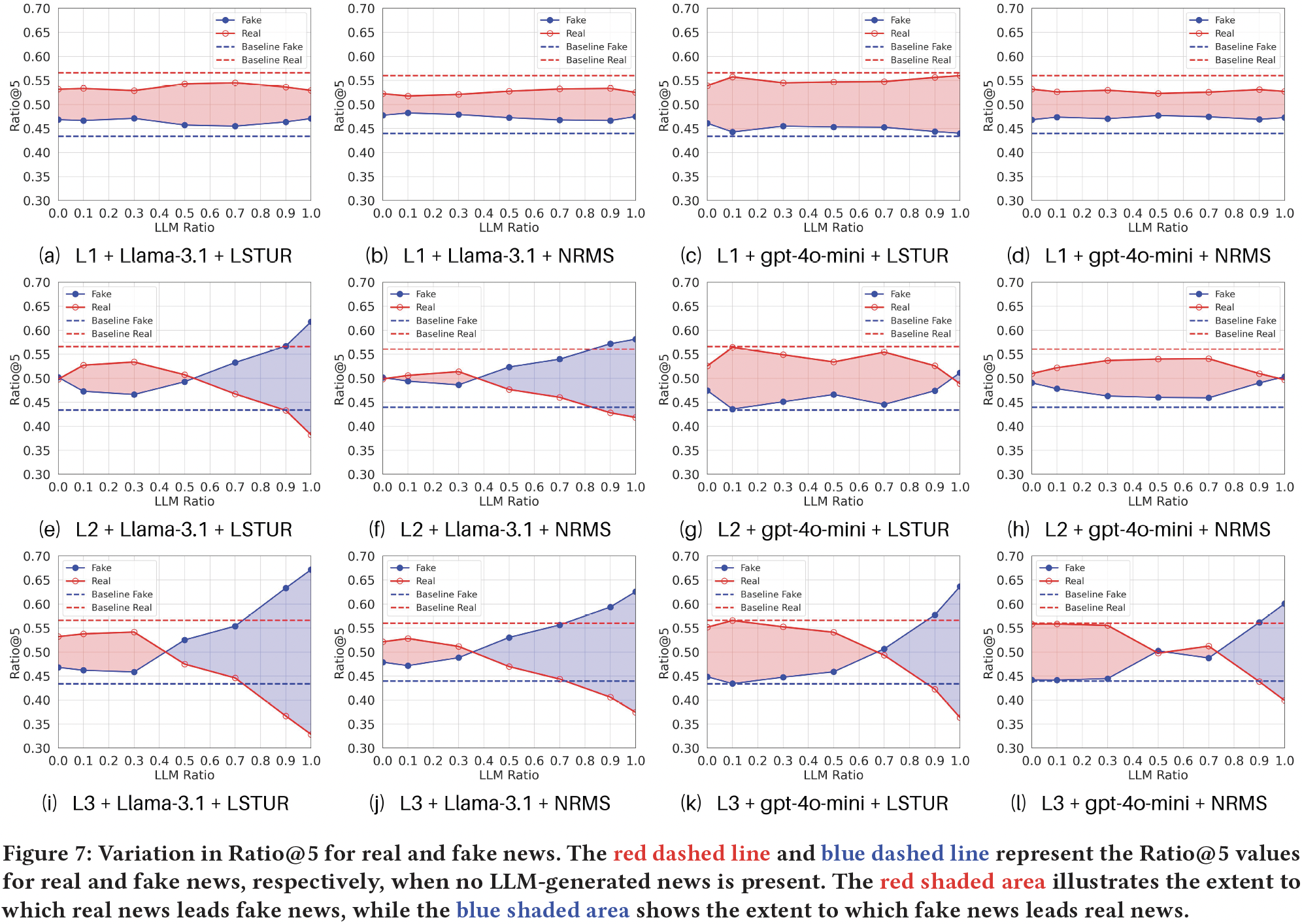
To simulate this phase, we constructed the training data using both human-written news and LLM-generated news. Similar to what was done in Phase 2, we randomly replaced t% of human-written news items in training data with their corresponding LLM-generated news items. For inference, we employed mixed history records in Phase 2 with the same LLM ratio as in training data, and mixed candidate lists used in both Phases 1 and 2.
The figure illustrates the changes in Ratio@5 for real and fake news as the LLM ratio varies. We observe that:
1) Overall, compared to the baseline, the presence of LLM-generated news in the training set consistently narrows the advantage of real news over fake news.
2) As the LLM ratio increases, this narrowing trend becomes more pronounced with higher faking levels. At L1, the advantage of real news remains stable. At L2, the real news advantage significantly diminishes and may even reverse. At L3, the ratio@5 of fake news eventually surpasses that of real news as the LLM ratio increases, indicating that the system favors fake news over real news.
Analysis: Why Truth Decay Occurs
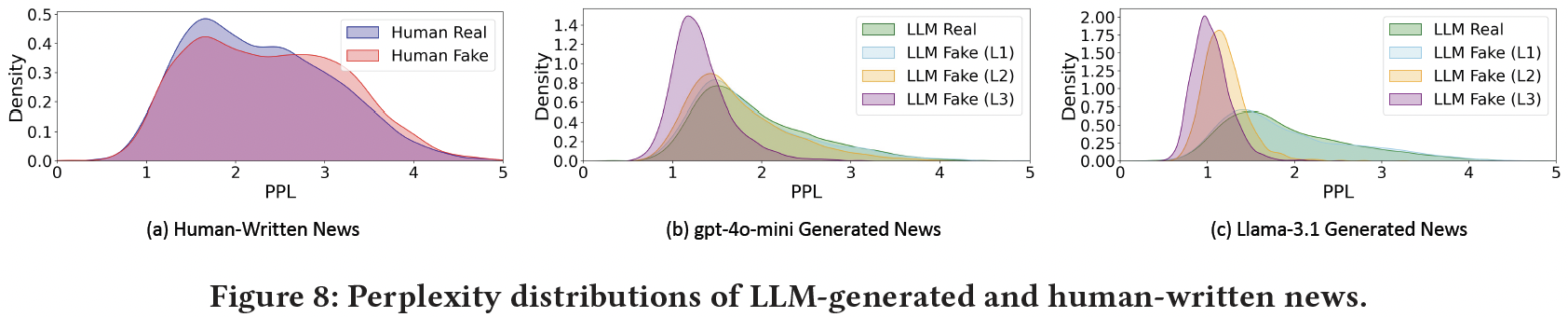
We perform further analysis to provide a possible understanding of the underlying mechanisms by which truth decay occurs. Inspired by existing works, we focus on the backbone PLM used in news recommendation, as its intrinsic bias in language modeling would significantly affect content understanding and item scoring. Specifically, we consider the perplexity metric because it indicates the model's familiarity with a text: The lower the perplexity, the more familiar the model is with the given text, possibly leading to better modeling.
The figure illustrates the perplexities (PPLs) of LLM-generated and human-written news. We observe that:
1) In human-written news, real news exhibits lower perplexity than fake news, indicating an advantage of real over fake news, which is aligned with the real news advantages observed in phase 0.
2) Differently from human-written news, LLM-generated fake news has lower perplexity than the real, corresponding to the emergence of truth decay when LLM-generated news is included. Moreover, the perplexity is lowered as the faking level increases, which provides an explanation about why L3 brings more significant truth decay than L1 and L2---with fewer constraints, generated news at L3 has lower perplexity and is more preferred by the backbone of news recommenders.